 |
By Chander Kant
linclusters (at) gmail.com
"Cluster" is an ambiguous term in computer industry. Depending on the vendor and specific contexts, a cluster may refer to wide a variety of environments. In general a cluster refers to a set of computer systems connected together. For the purposes of this book a cluster is set of computers which are connected to each other, and are physically located close to each other, in order to solve problems more efficiently. These types of clusters are also referred to as High Performance Computing (HPC) clusters, or simply Compute clusters.
Another popular usage of the term cluster is to describe High Availability environments. In this environment a computer system acts as the backup system to one or more primary systems. When there is a failure in a primary system, the critical applications running on that system are failed over to its designated backup system. Detailed usage and technology behind these types of clusters is outside the scope of this book. Nevertheless, we will touch upon specific usage of high availability technology within the context of compute clusters.
Clusters are becoming increasingly popular as computational resources both in research and commercial organizations. These organizations are favoring clusters over single large servers (We will be referring to the set of processing elements within the boundaries of single instantiation of an operating system as comprising a single server or a shared-memory system) for a wide variety of problems. The increasing popularity of the Linux operating system is adding fuel to this fire. Linux provides a very cost effective and open environment to build a cluster. Since its conception in the early nineties, Linux has been very popular with researchers. The open-source code of Linux allows researchers to customize the system to best suit their specific problems, and to do advanced computing research without getting tied to any specific system vendor. Starting in 1999 many system vendors started offering full production-level support on Linux platforms. This took Linux systems, and their clusters, out of the realm of early adopters into mainstream usage.
In this chapter we will begin by delineating various approaches to building parallel computing environments and compare and contrast them with clusters. We will go over benefits of deploying clusters as well as expose their downsides. We will then discuss two broad categories of compute clusters and their usage to solve problems from various fields. We will end the chapter by giving a high level description of the architecture of a cluster and introduce terminology to be used throughout the book.
Before discussing clusters in detail, let us examine different ways of putting various computational resources together to solve problems. As explained in a subsection below, the boundaries between various types of parallel systems have been blurred significantly, both because of new technologies as well as vendor marketing efforts. The simplified taxonomy in next sections will help us discuss various trade-offs between different technologies.
This class of systems have multiple CPUs within the boundary of a single operating system (OS) image. Design emphasis is put on scaling the OS to increasing number of CPUs, and providing an environment which allows a single application instance to scale on multiple CPUs. Symmetric multiprocessor (SMP) machines and implementations of Non-Uniform Memory Access (NUMA) systems in the late nineties belong to this category. All CPUs within the system can directly access the physical memory as well as any peripherals installed in the system.
Designers of Massively Parallel Processor (MPP) systems put emphasis on the scalability of the hardware. MPP systems have been designed to go up to hundreds, in some cases thousands, of processors. Processing elements (sometimes referred to as nodes) are connected together using a proprietary interconnect. Each node runs its own copy of the OS kernel (or microkernel).
Programmers view an MPP as having distributed memory. A processor cannot directly access the physical memory located in a remote node. The programmer or the compiler has to instruct the machine to transfer data from one node to another node on need basis. Faster and well controlled interconnects in MPPs have led to some attempts in providing a shared memory look-alike programming model on these machines. However, these attempts suffer from scalability and availability concerns.
In many organizations, especially those with some engineering design intent, individual users have powerful workstations on their desks. These workstations usually sit idle during off-work hours. Various innovative technologies make it possible to harness these idle cycles, hence providing an optimal use of the computing infrastructure.
In most environments these workstations are simply connected to the building local area network (LAN) and don't have a special high speed interconnect between them. A distributed resource manager controls the jobs submitted by users, and attempts to execute them on idle workstation(s). The Condor system developed at University of Wisconsin is an example of one such resource manager.
Given the ambiguity in the usage of terminology and blurred boundaries between various technologies, we will stick to the definition of clusters given by Pfister[]:
A cluster is a type of parallel or distributed system that:
The ``whole computer'' in above definition can have one or more processors built into a single operating system image.
The key differences between a cluster and a NOW are:
The key differences between a cluster and an MPP system are:
Beowulf is a popular term to describe Linux compute clusters. The term originated as the name of a project at NASA Goddard, which resulted in creation of a cluster system comprising of 16 nodes in 1994. From that time on Beowulf has evolved into a broader term, describing a genre of high performance computer systems with a very enthusiastic (and vocal!) community of supporters. What exactly constitues a Beowulf is a subject of debate. Some people characterize any Linux compute cluster as being a Beowulf. Other folks deem the exclusive use of commodity hardware, open-source software and open & standard protocols as key for a system to be called Beowulf. According to the latter view the Beowulf philosophy is to not get tied to any particular vendor for any component of the system. The extreme form of this view supports building even the individual cluster nodes themselves from pieces parts by separately buying motherboards, CPUs, memory chips etc. The authors of this book very much subscribe to the Beowulf philosopy, and support using commodity off-the-shelf components whenever appropriate. But we also believe that many organizations will benefit significantly by deploying advanced technologies, which are not commodity yet, in their Linux clusters. Some organizations will also find it more cost effective to deploy vendor integrated nodes, even integrated clusters, instead of building their own expertise to do so.
Many developments have blurred the boundaries between above mentioned types of systems. Their distinction, or lack thereof, is sometimes the subject of heated debates. This is a brief list of developments indicating the foray of one type of architecture into another architecture's domain:
The two key reasons for using clusters instead of a large system are price/performance and scalability. As system size becomes larger, the size of its installed base decreases quite rapidly. Thus the cost of producing technology to scale the system to higher number of processors is amortized to a relatively fewer number of systems. Hence single systems reach a point of diminishing returns beyond which it is not cost-effective to scale them except for a limited set of special applications.
Some benefits of clusters include:
A system in the cluster can be serviced without bringing rest of the cluster down. Also, additional computational resources can be added to a cluster while it is running the user workload. Hence a cluster maintains continuity of user operations in both of these cases. In similar situations a SMP system will require a complete shutdown and a restart.
It is important to mention some disadvantages of using clusters as opposed to a single large system. These should be closely considered while deciding an optimal computational resource for an organization. System administrators and programmers of the organization should actively take part in evaluating the following trade-offs.
A cluster increases the number of individual components in a computer center. Every server in a cluster has its own independent power supplies, network ports etc. The increased number of components and cables going across servers in a cluster partially offsets some of the RAS advantages mentioned above. It is easier to manage a single system as opposed to multiple servers in a cluster. There are a lot more system utilities available to manage computing resources within a single system than those which can help manage a cluster. As clusters increasingly find their way into commercial organizations, more cluster savvy tools will become available over time, which will bridge some of this gap.
In order for a cluster to scale to make effective use of multiple CPUs, the workload needs to be properly balanced on the cluster. Workload imbalance is easier to handle in a shared memory environment, because switching tasks across processors doesn't require too much data movement. On the other hand, on a cluster it tends to be very hard to move an already running task from one node to another. If the environment is such that workload balance cannot be controlled, a cluster may not provide good parallel efficiency.
Programming paradigms used on a cluster are usually different from those used on shared-memory systems. It is relatively easier to use parallelism in a shared-memory system, since the shared data is readily available. On a cluster, as in an MPP system, either the programmer or the compiler has to explicitly transport data from one node to another. Before deploying a cluster as a key resource in your environment, you should make sure that your system administrators and programmers are comfortable in working in a cluster environment.
There are two broad categories of compute clusters based on the computational resource usage characteristics of problem(s) being solved them: Throughput clusters and Capability clusters.
A throughput cluster is deployed to solve a lot of relatively small problems. A single compute node is capable of providing sufficient computational resources to solve any of these problems. These could be independent applications (We will be referring to the program developed by a software developer to solve a problem as an application, and a particular instantiation of the application will be referred to as a job. A job may be composed of one or more processes/threads.) or multiple instantiations of the same application.
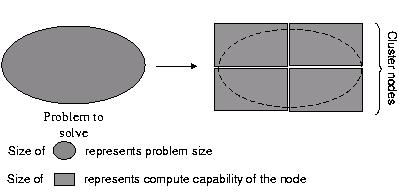
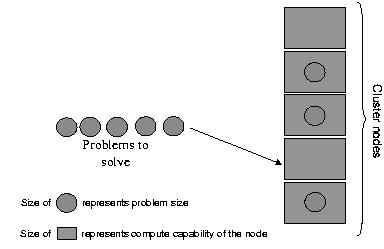
A cluster is deployed to optimally spread these problems on multiple compute nodes so that the overall workload can be executed on in parallel (see fig 1.1). A load balancing tool is used to optimally allocate compute nodes to address the needs of the users.
A capability cluster is deployed when a problem cannot be cost-effectively solved using a single server. As mentioned earlier, a set of small servers is significantly cheaper than a single system with same number of aggregate CPUs. So, a cluster is more cost-effective to deploy if it can execute the application at a comparable level of performance of a similar sized single system. In some extreme cases the resource requirements of a problem could be so large that a single system image cannot effectively scale to meet the demand.
Multiple nodes, in a capability cluster, coordinate with each other to solve the problem concurrently (see fig 1.2). A parallel programming technique is used to spread the load of a problem across compute nodes.
Scientists and engineers have been the predominant users of Linux clusters. These users range from an aerospace engineer simulating a trajectory to a financial engineer performing economic scenario analysis. New applications are getting ported to Linux clusters every day. Clusters are now finding aggressive acceptance into data mining applications, where a lot of largely independent data, e.g. clicks on a website, needs to be crunched for finding interesting and useful patterns.
Clusters are sometimes used as development or intermediary tools to assist specialized supercomputers. In many environments parallel programs are designed and tested on clusters and then deployed on, e.g., an MPP machine. Linux clusters are very popular in universities and research labs for teaching and experimenting with parallel and distributed computing technologies.
In next sections we provide some examples of clusters usage in specific areas and point out reasons for their preference.
Many of the computing problems in the areas of geophysics and seismology lend themselves for efficient solution on Linux clusters. Many big corporations, including global oil giants, have deployed clusters for oil and mineral exploration. Government agencies, as well as insurance companies, are using clusters to model effects of an earthquake for varied objectives like city planning, evaluating emergency readiness, etc. Astrophysicists are using clusters to simulate large and complex cosmic phenomena, like colliding galaxies. Numerical weather prediction models have been ported and optimized for Linux clusters. In fact the purpose of the very first Beowulf system built at NASA Goddard was to operate on the large data sets typically associated with applications in earth and space sciences.
Space, earth's core & its surface can be divided into smaller chunks and for some of these problems each chunk can be processed independent of the other. For example, an oil exploration project can divide the sea-floor into various areas. Nodes in a throughput cluster can then process the seismic data from these areas in parallel.
Linux clusters are widely used in established and emerging areas in the fields of bioinformatics and computational chemistry. Scientists can use numerical simulation of electronic structures of molecules to predict various chemical phenomena, without actual laboratory experimentation. This simulation can be highly computationally intensive, and benefits significantly from scalability of a cluster. Another exciting usage of Linux clusters is in the areas of gene sequencing and protein modeling. Applications in these clusters are used for such crucial areas as understanding diseases, designing drugs and improving agricultural output.
Many popular computational chemistry applications have been ported and tuned for Linux clusters. Examples include Gaussian[], GAMESS[], CHARMM[] etc. A typical computational chemistry environment has a mix of both sequential jobs (requiring a throughput cluster) and parallel jobs (requiring a capability cluster). Therefore the deployed clusters are hybrid in nature, providing tools for both throughput and capability requirements.
Clusters deployed in bioinformatics applications require not only the scalability of their number crunching capabilities, but also the scalability of their data storage and retrieval. For example, a system meant for sequencing of genomes requires access to a large amount of pre-existing sequence knowledge along with the capability of adding numerous new entries. Special databases have been designed to serve the purposes of such clusters.
Rendering refers to the process of transforming software scene descriptions into colored pixels. Rendering a sequence of frames to create an animation is one of the so called embarrassingly parallel applications. A cluster meant for rendering a set of frames is referred to as a Render farm.
A render farm is a throughput cluster, with each node capable of running a rendering algorithm. Even a small animation contains thousands of frames, and a single frame may take hours to get rendered. A render farm renders an animation in parallel, hence cutting down on production time. A Linux cluster was used to render the visual effects in the movie Titanic.
Artists submit the scenes of a film to a control server. The control server monitors the various nodes in the cluster to see availability of idle computing resources. It then submits the frame to an available CPU. The computing node renders the frame and sends it to a storage server (which may or may not be the same as the control server). The storage server makes sure that the frames are kept in the correct order as desired by the artists.
An advanced technique for exploiting the parallelism of rendering is to break a single frame into multiple segments, and spread these segments onto different nodes of the cluster. These nodes then send the rendered segments back to a master server. The master server usually has to do some post-processing on the frame after assembling all the segments. This technique is useful when fast rendering of an individual frame is desired.
A compute cluster consists of a lot of different hardware and software components with complex interactions between various components. In fig 1.3 we show a simplified abstraction of the key layers that form a cluster. Following sections give a brief overview of these layers.
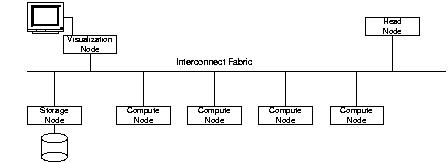
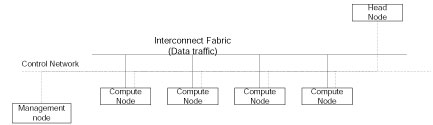
A typical compute cluster (see fig 1.4) consists of a set of nodes designated as compute nodes, and other nodes which provide various support functions for the compute nodes. These supporting nodes include head nodes, management nodes, storage nodes and visualization nodes. The compute nodes form the core of a cluster. Compute nodes are dedicated servers which constitute the processing power of the cluster. Compute nodes are connected using a dedicated interconnect fabric. This fabric is used for communicating data and control messages between the compute nodes. Some environments may require multiple interconnects to be used within a single cluster, E.g., an interconnect for fast data messages (usually connecting only the compute nodes), and another for slower control messages (see fig 1.5).
Compute nodes do not directly connect to the user network, instead a head node of the cluster is connected to the user network. The head node provides the interface of the cluster to the outside world. The users only communicate with the head node for solving their problems, or to check the status of their problem. The head node in turn coordinates the compute nodes to solve the problems submitted by the users. The head node in most configurations is a dedicated server. In some configurations the head node may also take the role of other supporting nodes.
A compute node in a cluster typically has very limited storage. Indeed some clusters are built using diskless compute servers. If the applications being run on the cluster require any significant amount of storage, a storage node is deployed. A storage node is a dedicated server and has the capability of storing and serving data for rest of the cluster nodes.
Many applications being deployed on a cluster may have a visualization component to them. This could be either real time visualization where the processed data gets visualized concurrently while the computation is going on, or based on post-processing where the processed data gets collected on a storage node and is visualized later on need basis. In both of these cases, a visualization node is deployed to provide the required capability of viewing the data. The visualization node is a workstation with good graphics capabilities.
Intuitive and effective management of a cluster tends to be of great importance in the overall success of a cluster implementation. Since a cluster is sum of many different parts including multiple computer systems, it is vital to be able to manage the cluster as a single entity, rather than managing each single component individually. Cluster management tools provide a single entity view to the system administrators.
Presence of a head node is key to this single entity view. Since the compute nodes are not connected to the user network, administrators only see the network address of the head node as the address of the cluster. All the compute nodes are hidden behind the head node. Hence, administrators don't need any reconfiguration of the public network whenever a change is made to the topology of compute nodes. Access and security of the cluster is also controlled solely through the head node.
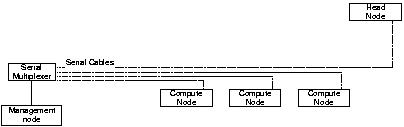
Most clusters have a dedicated management node, which has the capability of providing critical control of other nodes of the cluster (see fig 1.6). These controls include ability to get to the system console, ability to monitor the software and hardware of other nodes and ability to power-cycle any node on need basis. A management node is typically a workstation with a serial multiplexer device attached to it. This serial device enables the management node to communicate with rest of the nodes in the cluster even if the building network is down.
A capability cluster relies on ability of programmers to create distributed applications and ability of these applications to efficiently run on the cluster. There are many different parallel programming techniques deployed by programmers for their development purposes. If a cluster has compute nodes with more than one processor, the application developer must consider two levels of parallelism: Parallelism within a node (intra-node parallelism) and parallelism across nodes (inter-node parallelism). Intra-node parallelism uses the shared memory within a node, hence does not require explicit movement of data. Inter-node parallelism, on the other hand, requires data to be shipped across the interconnect fabric. There are three ways of implementing inter-node message traffic:
While the first approach can provide opportunities of very low level tuning, the code thus generated is very hard to maintain, and is not easily portable to different platforms. Currently the most popular mechanism of programming on Linux clusters is to use MPI library. For most of this book we will assume MPI based programming model for capability clusters. The concepts discussed will in general apply to other cluster programming approaches as well. We will point out the current limitations as well as advances made in the implementation of software layers which provide virtual shared memory.
First we start with the bottommost layer in fig 1.3. In the next chapter we explore in detail the key features of an individual cluster node and discuss the trade-offs between various choices.
I would very much appreciate comments, corrections or suggestions for additions:
linclusters (at) gmail.com
Copyright © 2005, LinuxClusters.com. All Rights Reserved.